Part #1: Redesigned reports and 30% discount
Part #3: Beta available and Hybrid analysis
On several occasions in the past, users have asked why we don’t import data from log files into some kind of database. The answer is still the same: using any kind of database actually significantly reduces performance, even with some of fast libraries like SQLite. Sure, it would be much easier to develop, but the trade-off on the users’ end would be enormous, if we want to follow the original idea of web log analyzer capable for free on-the-fly filtering and creating ad-hoc reports.
So Web Log Storming utilizes series of our own algorithms to:
- Parse and analyze text log files as fast as possible
- Organize data in complex model, so it doesn’t take any more memory than it’s necessary
- Provide fast routines to search and filter reports “on-the-fly” by any available data
It is clear that any of third-party libraries, database or other, cannot be more optimized for specific tasks that Web Log Storming requires, then those developed by ourselves from the scratch.
Still, starting with version 3, we have introduced a small improvement with optional log files caching. Basically, Web Log Storming will now analyze text log files, convert to numbers, dates, IP addresses, etc, and then the new step: save parsed data to cache files in format suitable for further usage. Next time when you analyze same log file, software will check if cache exists and read a prepared cache, instead of parsing text file again.
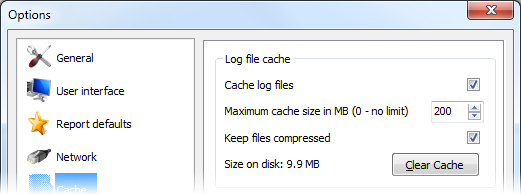
Naturally, in case caching is enabled, first reading will be slower for the exact time needed to save data to the disk, but each next reading will be significantly faster for the time needed to convert texts to operable data. The speed change will depend on various factors, such is the typical size of individual log files and your preference if you want to keep cache compressed or not, etc. According to our tests, here’s a approximate rough speed comparison:
| No caching | Uncompressed | Compressed | |
| First analyzing | 100% | 100-120% | 120-150% |
| Each future analyzing | 100% | 50-70% | 70-90% |
| Combined first +4 future |
100% | 60-80% | 80-102% |
| Combined first +9 future | 100% | 55-75% | 75-96% |
| Combined first +49 future |
100% | 51-71% | 71-91% |
| Additional space on the disk | 0% | 100% | 10-15% |
Typically, for moderate sized log files, you can expect a better performance (closer to lower ranges). For very small individual files (up to few kilobytes) or very large files (hundreds of megabytes or more), caching might not be such a good choice.
As you can see, best total speed improvement is with uncompressed cache, but at the cost of the additional disk space. By setting a caching options, you can decide what works best in your case.
Upgrade policy and “Early Bird” 30% discount
As our users probably already know, we switched to subscription upgrade model years ago. That’s why we don’t specifically charge for major updates like this one: update is free for anyone who bought or upgraded within at least a year before a release day or for anyone who bought a lifetime license.
So feel free to download and try current version and, if you decide to buy even today, you will get version 3 for free. As a special promotion, you can use this coupon for 30% discount:
WLS89445EARLYBIRD
The coupon applies to any purchase (new license or an upgrade) and will be valid until v3.0 is released.
* * *
Feel free to send us your thoughts regarding version 3, either by commenting here or by using a contact form. We’ll be happy to hear your opinion.